Web Scraping Solutions
Never worry about blocks again. FlashID lets you scrape data like a real user, with complete automation support to maximize efficiency while staying undetected.
Be Human in a Digital World
Don't let anti-bot systems block your research. FlashID perfectly masks technical identifiers that websites check, making your browser fingerprint indistinguishable from a real user's every single time.

Multiple Identities, Zero Blocks
Scale up your data collection safely. FlashID gives each browser session a unique digital identity with different IPs and fingerprints, preventing account suspensions even during intensive scraping operations.
Get Started Now
Browse Like a Human, Not a Bot
Advanced websites can detect and block scripts. FlashID mimics genuine human browsing patterns with full JavaScript support, letting you access dynamic content that's protected by sophisticated anti-scraping systems.
Get Started Now
Unique Identity, Unlimited Data
Sites block repetitive access patterns, not just IPs. FlashID solves this by generating a completely new browser fingerprint for each session, dramatically increasing your success rate and data collection capacity.
Get Started Now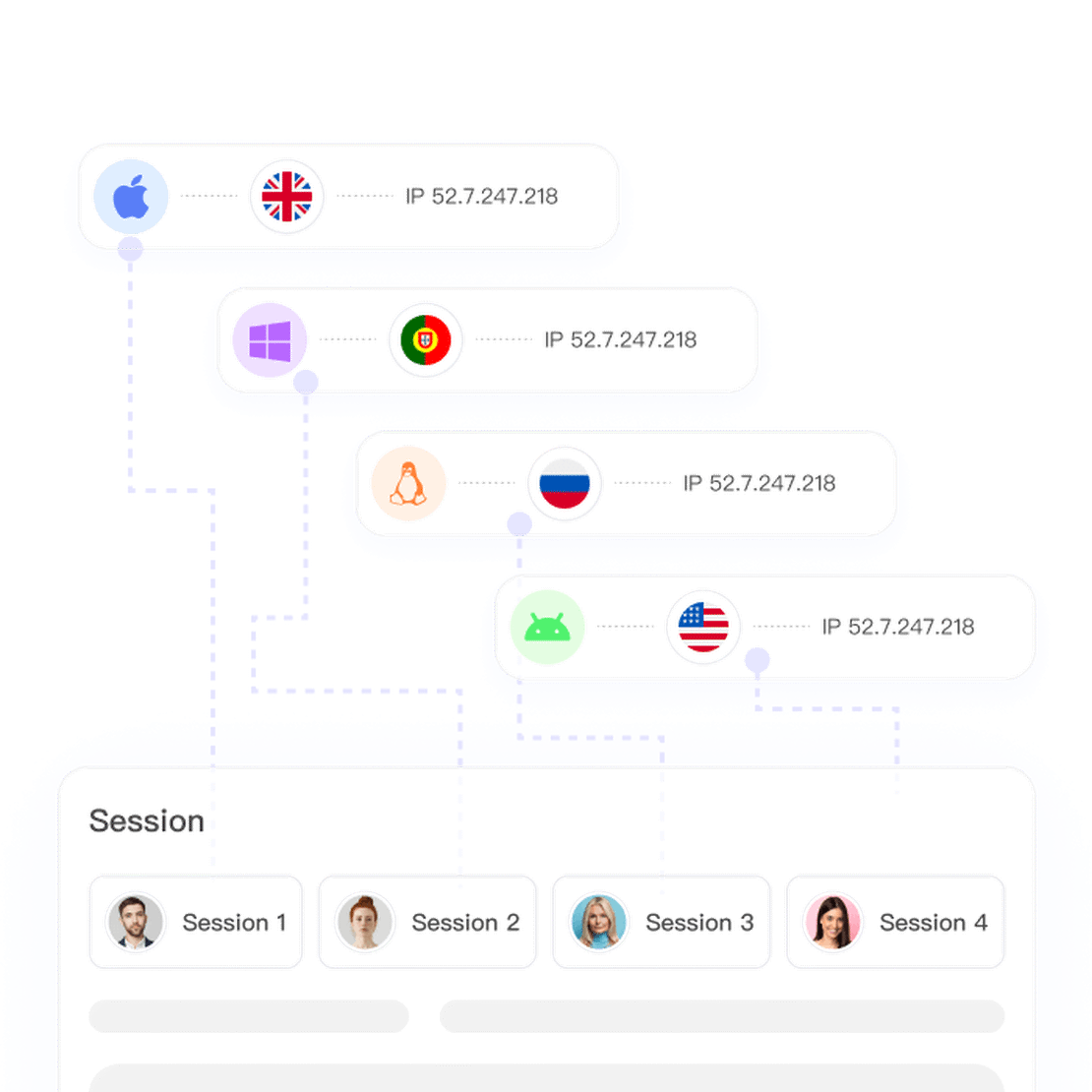
Scrape Without Limits
Turn data collection into your competitive advantage. FlashID ensures your scraping operations stay under the radar while delivering clean, actionable data every time.

Why Choose FlashID for Web Scraping
Web scraping faces challenges like IP blocks, fingerprint detection, and data collection inefficiency. FlashID provides isolated browser environments to bypass anti-bot measures, increase scraping success rates, and streamline your data collection operations.
Bypass Advanced Anti-Scraping Protections
Runs pure Chrome profiles with unique fingerprints that bypass Cloudflare, Imperva, DataDome and other bot detection systems without CAPTCHAs or blocks.
Prevent IP & Browser Fingerprint Bans
Isolates each scraping session with unique digital fingerprints and clean environments, preventing cross-contamination and detection patterns.
Seamless Integration with Scraping Tools
Full compatibility with Puppeteer, Selenium, Playwright and other automation libraries, plus built-in RPA features for efficient data extraction workflows.
Scale Your Data Collection Operations
Run multiple concurrent scraping sessions with different identities, rotating proxies, and unique parameters to maximize data collection capacity.
Centralized Scraping Project Management
Organize multiple scraping projects in one interface with custom session configurations, scheduled runs, and monitoring capabilities.
Reliable Performance & Data Integrity
Ensure consistent scraping results with stable browser environments and secure local storage for collected data, cookies, and session information.
In which web scraping scenarios do teams rely on FlashID as a core solution?
Anti-scraping blocks (CAPTCHAs, IP bans), incomplete data, and persistent tracking derail web scraping. FlashID leverages top-tier anti-detection tech to build authentic user environments, enabling stable, large-scale, and accurate data extraction.
One scraping IP/account gets blocked, and all linked scraping tools are banned
Anti-scraping systems block access, leading to incomplete data
Switching scraping environments for different sites is time-consuming
Persistent fingerprint tracking leads to permanent site bans
Scaling scraping tasks is inefficient with generic tools
Cross-regional scraping fails to get local data






Connect all your platform accounts
Thanks to our fingerprint technology, you no longer need to worry about your account being at risk, you just need to focus on your business.
Client Success Stories Trusted Worldwide
Operations Manager, Ad Agency Plus
Operations Manager, Growth Agency
Cybersecurity Researcher, Privacy Institute